📌 주의: 해당 글은 잘못된 내용이 포함 되어 있을 수 있습니다.
혹시 잘못된 내용을 발견 하신다면 댓글로 알려주시면 감사 합니다!
🌱 [ 배경 ]
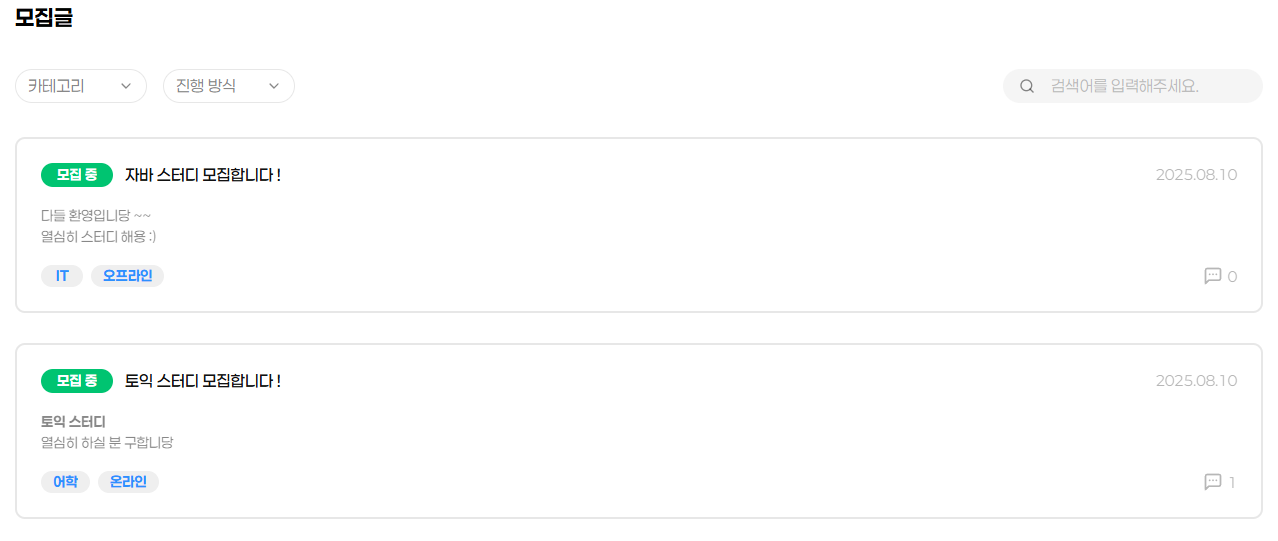
스터디 관리 플랫폼 Wibby 메인 페이지는 스터디 모집글 검색이 있습니다. ( Wibby )
카테고리, 진행 방식, 검색어를 사용 하여 모집글을 검색할 수 있습니다.
만약 모집글의 데이터가 많아 진다면 어떻게 될까요?
🌱 [ 더미 데이터 생성 ]
- 어플리케이션 빈 생성 및 의존성 주입 완료 후 CommandLineRunner 실행
- 모집글 백만개 생성
@Slf4j
@RequiredArgsConstructor
@Component
public class SearchLoader implements CommandLineRunner {
private static final int REPEAT_COUNT = 100_0000;
private static final int BATCH_SIZE = 1000;
private final EntityManager em;
private final SearchLoaderUtils utils;
@Transactional
@Override
public void run(String... args) throws Exception {
log.info("배치 작업 시작");
long startMillis = System.currentTimeMillis();
for (int batchIndex = 0; batchIndex < REPEAT_COUNT / BATCH_SIZE;batchIndex++) {
for (int i = 0; i < BATCH_SIZE; i++) {
Study study = createStudy(
utils.getRandomCategory(),
utils.getRandomStudyType()
);
em.persist(study);
RecruitmentPost post = createPost(study, utils.getRandomNumber());
em.persist(post);
}
em.flush();
em.clear();
}
long endMillis = System.currentTimeMillis();
log.info("소요 시간 = {} 초", (endMillis - startMillis) / 1000);
}
private RecruitmentPost createPost(Study study, int number) {
return createPost(
study.getId(),
"제목" + number,
"내용" + number,
RecruitmentPostStatus.IN_PROGRESS
);
}
private Study createStudy(Category category, StudyType studyType) {
return Study.builder()
.category(category)
.studyType(studyType)
.build();
}
private RecruitmentPost createPost(long studyId, String subject, String content, RecruitmentPostStatus status) {
return RecruitmentPost.builder()
.studyId(studyId)
.subject(subject)
.content(content)
.status(status)
.build();
}
}
7분에 걸쳐 모집글 백만개가 생성 되었습니다.


🌱 [ 테스트 ]
이제 테스트를 통해 모집글 검색을 해보겠습니다.
검색어를 제외한 카테고리와 스터디 타입을 고르고 2개를 찾아 오는 쿼리 입니다.
@DisplayName("모집글을 검색 합니다.")
@Test
void search() {
//given
Study study1 = createStudy("자바 스터디", Category.IT, ONLINE);
Study study2 = createStudy("클라이밍 동아리", Category.HOBBY, OFFLINE);
studyRepository.saveAll(List.of(study1, study2));
RecruitmentPost post1 = createRecruitmentPost(
study1.getId(), userId, "모집글 제목1", "내용1", IN_PROGRESS
);
RecruitmentPost post2 = createRecruitmentPost(
study2.getId(), userId, "모집글 제목2", "내용2", IN_PROGRESS
);
recruitmentPostRepository.saveAll(List.of(post1, post2));
List<RecruitmentPostComment> comments = List.of(
createPostComment(post1, userId, "댓글1"),
createPostComment(post2, userId, "댓글2"),
createPostComment(post2, userId, "댓글3")
);
commentRepository.saveAll(comments);
//when
RecruitmentPostPagingInfo result = recruitmentPostService.search(
PageRequest.of(0, 2),
Category.IT, ONLINE,
null,
null
);
//then
assertThat(result.getPostInfos()).hasSize(1)
.extracting("category", "subject", "commentCount")
.containsExactlyInAnyOrder(
Tuple.tuple(Category.IT.name(), "모집글 제목1", 1)
);
}
실제 검색 쿼리를 실행 하면 아래와 같이 나오게 됩니다.
얼마나 시간이 걸리는지 확인 하기 위해 검색 쿼리만 따로 실행을 해보겠습니다.


쿼리 실행시 5초의 시간이 걸립니다.
검색 한번에 실제로 5초가 걸린다면... 사용자들이 많이 불편을 겪게 되겠죠
개선을 위해 왜 쿼리가 오래 걸리는지 실행계획을 통해 살펴 보겠습니다.
🌱 [ 실행 계획 ]
select 앞에 explain 키워드를 붙인 후 쿼리 실행시 실행 계획을 볼 수 있습니다.

간단히 각 칼럼의 의미를 정리 하겠습니다.
| 칼럼 | 의미 |
| id | select 쿼리별로 부여되는 식별자 |
| select_type | select 쿼리의 타입 |
| table | 사용된 테이블 혹은 별칭 |
| type | ★ 테이블 접근 방법 |
| key | 사용된 인덱스 |
| rows | 테이블에 접근한 레코드 건수 |
| filtered | where 조건등을 통해 선택된 레코드 비율 |
| extra | 실행 과정 중 성능에 관한 문장 표시 |
type도 대표적인 것만 정리해 보겠습니다. 위 순서부터 성능상 빠른 순서 입니다.
| type | 의미 |
| const | 동등 조건 & 대상이 하나일 때 ( 유니크 인덱스, 기본키 ) |
| ref | 동등 조건 비교 & 대상이 하나가 아닌 경우 |
| range | >=, <= 와 같이 범위 스캔일 때 사용 |
| ★ index | 인덱스를 풀스캔 |
| all | 테이블 풀스캔 |
[ 모집글 ]
- type: ALL ( 테이블 풀 스캔 )
- filtered: 50 ( activated = true 조건에 맞는 튜플이 50% )
- extra: Using filesort ( 인덱스를 통한 정렬x, 자체적으로 정렬, 성능이 좋지 않음 )
[ 스터디 ]
- type: eq_ref ( 조인 조건이 PK/unique )
- key: 클러스터 인덱스
- filtered: 1 ( study_type = 'ONLINE' and category = 'IT' 조건에 맞는 row 5% )
🌱 [ 실행 계획 분석 ]
explain analyze 사용 시 실제 쿼리를 실행 하고 분석할 수 있습니다.


- 모집글 테이블 스캔 ( activated = true )
- 모집글 created_date desc 정렬
- 모집글과 스터디 조인
- 스터디 클러스터 인덱스 조회 및 스터디 필터링 type = 'ONLINE' and category = 'IT'
🌱 [ 인덱스 설정 ]
- 검색 조건 activated ( soft delete )
- 정렬 조건 created_date
- ( activated, created_date Desc ) 복합 인덱스 설정

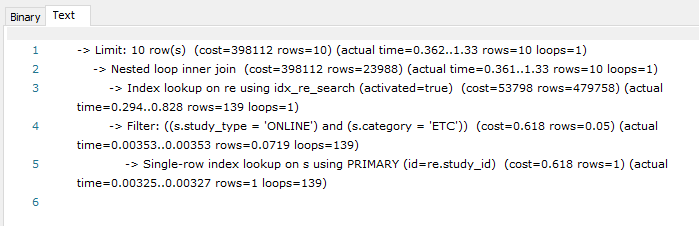
- 모집글 검색 인덱스 activated = true 스캔
- 스터디 클러스터 인덱스를 통해 스터디를 한건씩 조회 ( 이 과정을 반복 )
- 10건을 찾으면 종료 ( Limit = 필요한 레코드 건수만 준비되면 즉시 쿼리 종료 )
실제 쿼리 수행시 상수 시간이 걸림을 확인할 수 있습니다!
( 카테고리 혹은 스터디 타입이 없는 경우에도 똑같이 동작 )

'DB' 카테고리의 다른 글
| [ MySQL ] FullText Index (0) | 2025.09.16 |
|---|
